Hi! This week, I’ve been exploring options for a Horizon Environment that applies specific rules based on users’ origins (network addresses / IP addresses). For instance, certain users should be redirected to a Load Balancer with Unified Access Gateways (UAGs), while others should be sent directly to Connection Servers. The goal is to establish fine granularity and to test redirects from one load balancer to another for less trusted source networks, in order to enforce Multi-Factor Authentication (MFA) for such users.
The test lab consists out of:
- Horizon Connection Server (labcs1)
- 2 x Unified Access Gateway (labug1 & labug2)
- 2 x HAProxy LB (lablb1 & lablb2)
- “simulated” Workstations 172.16.0.20 & .21
- Virtual RDS labcl1
Leveraging on HAProxy ACLs the traffic should – depending on the originating IP address (.21 or default) – either be redirected through lablb2 and its connected UAG or just pass straight away towards the connection server labcs1.
Why this can be useful?
Imagine a scenario in which the end users are connecting from less trusted networks (e.g. through VPN zone) and you want to tunnel the session to hide the desktops in the backend or to enable MFA on UAGs in this path. Of course you could share two endpoints for the Users or work with DNS to point them to different LTMs. But still there might be some scenarios in which you want to work with redirects on the first LTM in the chain, e.g. when manipulating DNS is not possible for any reason.
So, lets get into it starting with the drawing of the lab.
Infra Drawing

The most important aspect is the LB configuration. lablb1 is a HAProxy Appliance which works as L7 Loadbalancer configured with an ACL rules:
When source IP matches 172.16.0.21 it is redirected via HTTP 302 to lablb2.
Important: When the path contains /broker/xml it is redirected via HTTP 307 to lablb2, otherwise the connection via Horizon Client will not work. (HTTP 403 or HTTP 405 error will occure)
# Sample HAProxy configuration of lablb1
frontend incoming_ssl_traffic
bind *:443 ssl crt /certs/cert.pem
mode http
option http-server-close
option forwardfor
acl source_ip_is_lablb2 src 172.16.0.21
acl path_is_broker_xml path_beg /broker/xml
http-request redirect location https://lablb2.lab.local/broker/xml code 307 if source_ip_is_lablb2 path_is_broker_xml
http-request redirect location https://lablb2.lab.local/ code 302 if source_ip_is_lablb2 !path_is_broker_xml
default_backend memberservers_backend
backend memberservers_backend
mode http
balance roundrobin
server member1 172.16.0.31:443 check
Instead the lablb2 configuration works in L4 mode, accepts TCP 443 (primary session protocol) and TCP 8443 (secondary session protocol) for BLAST traffic.
# Sample HAProxy configuration of lablb2
frontend incoming_443
bind *:443
mode tcp
default_backend myservers_443
frontend incoming_8443
bind *:8443
mode tcp
default_backend myservers_8443
backend myservers_443
mode tcp
balance source
server labug1.lab.local 172.16.0.41:443 check
server labug1.lab.local 172.16.0.42:443 check
backend myservers_8443
mode tcp
balance source
server labug1.lab.local 172.16.0.41:8443 check
server labug1.lab.local 172.16.0.42:8443 checkI have also tested to run lablb2 in L7 mode, however it was not possible to establish a tunneled session. I have always encountered this error:
Could not establish tunnel connectionThe Loadbalancing Methods
As per this article: https://techzone.vmware.com/resource/load-balancing-unified-access-gateway-horizon#secondary-horizon-protocols VMware supports 3 methods of load balancing UAGs:
- Source IP Affinity
- Multiple Port Number Groups
- Multiple VIPs
In the lab method 1 was used. However, there might be scenarios where it is not possible to rely on source ip affinity. In such case my favourite option is ‘Multiple Port Number Groups’ with a 1:1 mapping of UAG and Connection Server (UAG will automatically shut off its service when there is an issue on a connection server). I favour this method because the traffic flow is clear and transparent which is not always the case for the other methods, especially in large environments.
I do not touch in this post persistence or stickiness settings, just be aware to study this KB carefully before starting a deployment: https://kb.vmware.com/s/article/56636
There is a default heartbeat interval of 30 minutes that should be respected, if this is missed 3 times (90 minutes) the session will drop.
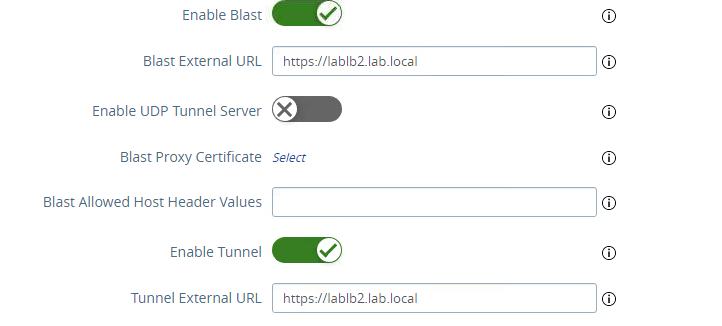
The UAG configuration with Source IP Affinity configuration
With source ip affinity the configuration is very simple, within the Horizon Settings section the Blast External URL and Tunnel External URL need to be configured to point to https://lablb2.lab.local by default the Blast External URL will point to TCP 8443 while the Tunnel External URL is on TCP 443. The Blast External URL can also be changed to TCP 443 or other ports if desired.
Testing the configuration
To verify if the configuration works I run multiple connection attempts from the simulated test workstations 172.16.0.20 and .21. Both test workstations were able to connect to a Desktop via Browser and via Horizon Client. For .21 the redirect to lablb2 works as desired and therefore .21 was able to establish a tunneled session.
Instead for the test workstation .20 no redirect was in place and it directly established the session with the Desktop without being tunneld through a UAG.